빅데이터 분석 거버넌스
개요
| 개념 | 빅데이터 거버넌스는 대용량·다양성·실시간성을 갖는 빅데이터를 대상으로, 수집·저장·처리·분석·활용 전 과정에 대한 표준, 품질, 보안, 메타데이터, 권한 및 플랫폼 운영체계를 통합 관리하는 체계 |
| 개념도 |  |
체계
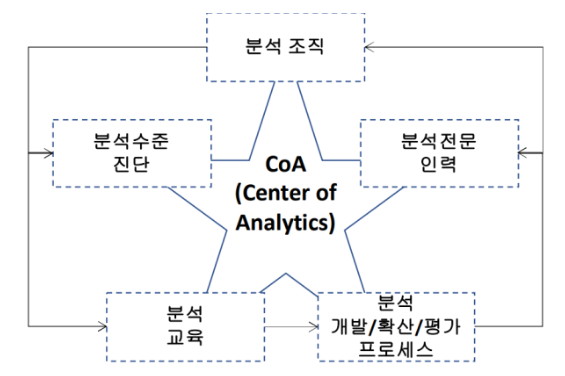 |
| 구분 | 상세설명 | 업무 |
| 분석 프로세스 | - 요건정의, 모델링 - 검증 및 테스트, 적용 |
- EDA(탐색적 데이터 분석) - CDA(확증적 데이터 분석) |
| 분석 전문 인력 | - 기초통계학 및 분석 방법에 대한 지식과 분석 경험 | - 데이터 사이언티스트 |
| 분석 조직 | - 데이터 분석 가치 발굴 및 과제 정의 - 인사이트 실행 |
- 데이터분석 컨트롤 타워 |
| 분석수준 진단 | 데이터 분석의 도입 여부와 활용에 대한 명확한 분석 수준에 대한 점검 | - 분석 준비도 - 분석 성숙도 |
| 분석 교육 | - 데이터 훈련 프로그램 진행 - 비즈니스 전체 분야 데이터 분석 업무 활용 |
- 가설 검증 능력 확보 |
- 데이터 분석의 도입 여부와 활용에 대한 명확한 분석수준에 대한 점검을 진행하고 이를 통해 분석 방향성 결정
빅데이터 분석 방법론
데이터 핵심 가치 추출 및 활용, 데이터 분석 방법론의 필요성
 |
| 구분 | KDD | CRISP-DM (Cross Industry Standard Process For DataMining) |
SEMMA |
| 개념 | Knowledge(지식) 기반 즉, Database의 데이터를 통해 통계적 패턴이나 지식을 찾기 위한 표준화된 처리 절차와 방법에 대한 데이터 분석 방법론 ( 데이터에서 의미 있는 지식을 찾아내기 위한 전체 발견 절차) 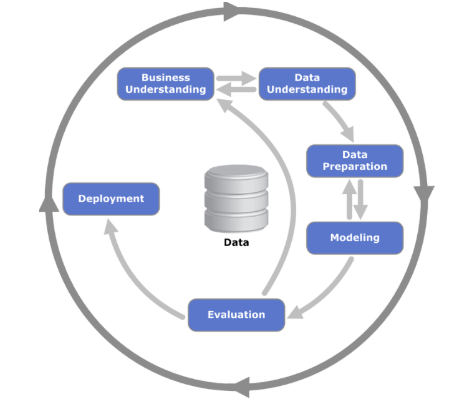 |
비즈니스의 이해 기반으로 데이터 이해, 모델링, 평가 및 배포 등 데이터 분석 목적의 6단계로 진행되는 데이터 마이닝 및 분석 방법론 ( 현업 문제를 이해하고 분석해서 실제 활용까지 연결하는 방법론) |
SAS사 주도 통계적 방법 기반으로 데이터 샘플링, 탐색, 수정, 모델링, 검증 등의 기능을 제공하여 사용자가 쉽게 마이닝이 가능한 데이터 분석 방법론 ( 데이터를 뽑고 살펴보고 고치고 모델 만들고 검증하는 실무 중심 분석 절차) |
| 기반 기술 | 프로파일링 기술 기반 | 4단계 계층적 프로세스 모델 기반 | 통계 기술 기반 |
| 추출 대상 | Database | 도메인 지식 | 자사 기능 |
| 주요 특징 | 기술과 데이터베이스 중심으로 정리 | 비즈니스 상황에 따른 결과 해석 (비즈니스 이해, 데이터 마이닝 방법론) |
기술적 관점 기반의 분석 (비즈니스 관점 분석이 미약함) |
| 주요 기술 | Classification(분류) Clustering(군집) Predictive(예측) |
RACI 차트(역할별 책임) Exploratory Data Analysis(EDA) |
Correlation Analysis Neural Network Logistic Regression |
| 활용 분야 | 데이터 마이닝 데이터 패턴 해석 ML/AI 응용 |
비즈니스 데이터 분석 비즈 애플리케이션 적용 |
일반 데이터 분석 |
| 동향 | 연구활용 | IBM SPSS 중점 추진 | SAS 통계 패키지 활용 |
| 반복 여부 | 평가 결과 미 충족 시 반복 수행 | 단계별 반복 수행(분석 품질 향상) | 목표 도달까지 반복 순환 |
| 분석 단계 | 5단계 | 6단계 | 5단계 |
| 분석 상세 절차 |
 |
 |
 |
- 각 방법론마다 분석 대상 및 목적이 상이하여, 대상/목적에 따른 적합한 데이터 분석 방법론 선정이 중요함
CRISP-DM
| 개념 | - 계층적 프로세스 모델로, 비즈니스 이해를 바탕으로 6단계로 수행하는 데이터 마이닝 방법론 |
| 특징 | 비즈니스 이해, 데이터 마이닝 |
빅데이터 분석 시 고려사항
| 구분 | 내용 |
| 인력/조직 | - 분석 전문가 영입 - 분석 전문가 교육 과정 - 관리자 및 운영자의 데이터 분석능력 제고 - 경영진 분석 업무 이해 능력 제고 - 사용자 적극적 참여 및 피드백·개선 |
| 기술/프로세스 | - 업무에 적합한 분석 기법 사용 - 분석 기법 정기적 개선 및 검증·평가 - 시스템 데이터 통합 - EAI, ETL, ELT 적극 활용 - 분석 성능을 고려한 모델 및 알고리즘 선정 |
| 비즈니스/Data | - 분석에 필요한 데이터 신뢰성·적시성 고려 - MDM(기준데이터관리) 도입 - 예측·해석·시각화 등 최적화 수행 - 업무 도메인 성격에 부합하는 데이터 분석 방법론 선택 |
빅데이터 플랫폼 아키텍처
개요
| 개념 | - 다양한 데이터를 처리/분석하여 지식을 추출하고, 이를기반으로 지능화된 서비스를 제공하는데 필요한 IT 환경 |
| 개념도 |  |
빅데이터 플랫폼 인프라 구조 설계
가. 개념도
 |
나. 상세설명
| 구분 | 특징 | 설명 |
| 사용자 계층 | 분석 애플리케이션 (Analytic Applications) |
- 리포팅이나 시각화 툴 등이 포함되며, 예측 분석 툴로는 통계 기반의 SPSS, SAS, R 등이 있음 |
| 사용자 인터페이스 (Visualization & Discovery / Application Development / Systems Management) |
- 사용자 인터페이스는 크게 비즈니스 현업 사용자, 개발자, 관리자로 나뉨 | |
| 데이터 처리 계층 | 가속기 (Accelerators) | - 소프트웨어 성능을 높이는 도구로, 웹 애플리케이션 가속기는 사이트 접속 시간이나 다운로드 속도 향상에 사용됨 |
| 데이터 관리 계층 | 정보 통합과 거버넌스 (Information Integration & Governance) |
- 빅데이터 플랫폼은 정보 통합 차원에서 구조적, 비구조적, 스트리밍의 여러 데이터를 다뤄야 함 -거버넌스 측면에서는 개인정보 보안, 빅데이터 관련 메타데이터, 데이터 생명주기 관리와 마스터 데이터 연계가 있음 |
빅데이터 플랫폼 데이터 구조 설계
가. 개념도
 |
나. 상세설명
| 데이터 유형 | 데이터 형태 | 기술 | 특징 | 데이터 종류 |
| 정형 데이터 | RDB | - RDB - Aggregator |
- 관계형 데이터베이스에서 정형 데이터를 수집하여 HDFS나 HBase 등의 NoSQL에 저장 | - RDB - 스프레드시트 등 |
| 반정형 데이터 | HTML | - Crawling | - SNS, 뉴스, 웹 정보 등 인터넷상의 웹 문서와 정보 수집 | - HTML, XML, JSON, 웹문서, 웹로그, 센서 데이터 등 |
| 실시간 데이터 |
- Open API | - 서비스, 정보, 데이터 등을 개방된 API로 수집 | ||
| XML | - RSS | - 웹 기반의 최신 정보를 공유하기 위한 서비스 | ||
| Log 데이터 | - Log Aggregator | - 웹서버 로그, 웹로그, 트랜잭션 로그 등 각종 로그 데이터 | ||
| 비정형 데이터 | File 데이터 | - FTP | - CP/IP 프로토콜을 활용하는 인터넷 서버를 통한 각종 파일 송수신 | - 소셜 데이터, 문서(워드, 한글), 이미지, 오디오, 비디오 등 |
| WMV, MP3 등 | - Streaming | - 인터넷에서 음성, 오디오, 비디오 데이터를 실시간 수집 |
- 정형 데이터는 전통적인 관계형 데이터베이스가 가장 일반적으로, 데이터는 칼럼과 그 칼럼의 데이터 속성에 맞는 데이터로 레코드(행)를 구성
- 비정형 데이터는 숫자, 숫자, 문자 등이 섞여있는, 구조가 정해져 있지 않은 데이터로, Key와 그에 맞는 Value의 쌍 형태로 구성
- 반정형 데이터는 HTML과 XML이 대표적임
빅데이터 입출력 구조 설계
가. 개념도
 |
나. 상세설명
| 구분 | 목적 | 설명 |
| Hadoop | 빅데이터 처리 솔루션 | - 여러 개의 컴퓨터를 하나로 묶어 대용량 데이터를 처리 |
| HDFS | 하둡의 저장소 역할 | - 네트워크로 연결된 여러 머신의 스토리지를 관리하는 역할 |
| MapReduce | 대용량 데이터 분산 처리 | - 데이터 처리를 위한 프로그래밍 모델 |
| Map단계 | Input Data 가공 | - 데이터를 가공하여 사용자가 원하는 Key-Value로 변환 - Split: 데이터 입력의 크기 |
| Reduce단계 | Key 정보 추출 | - 중간 산출물을 Key 기준으로 분배하고, 사용자가 정의한 방법으로 Key 정보를 추출 |
시스템 검증 방안
 |
- 빅데이터 시스템은 데이터 소스를 하둡 HDFS에 저장하고, 저장된 데이터는 MapReduce를 통해 처리함
- 처리된 데이터는 결과값으로 출력되며, 이는 분석 리포팅이나 트랜잭션 시스템 처리를 위해 데이터 웨어하우스로 이전됨
- 빅데이터 처리의 이 3단계마다 테스트를 수행하여 데이터가 오류 없이 처리되도록 해야 함
빅데이터 플랫폼 구축시 고려사항
| 구분 | 고려사항 | 설명 |
| 데이터 | 수집·저장체계 | 다양한 데이터를 안정적으로 수집·저장할 수 있어야 함 |
| 품질·표준관리 | 데이터 정합성, 표준화, 메타데이터 관리가 확보되어야 함 | |
| 시스템 | 확장성·성능 | 대용량 데이터 증가에 대응할 수 있는 분산처리와 성능 확보 필요 |
| 가용성·복구성 | 장애 발생 시에도 서비스 지속이 가능하도록 이중화, 백업, 복구체계 필요 | |
| 운영 | 거버넌스·연계성 | 조직, 역할, 권한, 운영절차와 타 시스템 연계체계 마련 필요 |
| 보안 | 접근통제·보호 | 개인정보, 중요정보 보호를 위한 권한관리와 보안대책 필요 |
'Study Note > DB' 카테고리의 다른 글
| [데이터마이닝> 비정형 데이터 마이닝] 텍스트마이닝, 사회연결망 분석(SNA) (0) | 2026.04.16 |
|---|---|
| [빅데이터 분석> 결과해석] 시각화 (0) | 2026.04.16 |
| [데이터 품질관리> 데이터 경영] 데이터거버넌스, MDM (0) | 2026.04.14 |
| [자료구조론> 트랜잭션] 트랜잭션, ACID, 격리레벨 (0) | 2026.04.14 |
| [DBMS/분산파일처리] NoSQL (0) | 2026.04.14 |